Hàm REGEX
Mục lục
I. Giới thiệu
REGEXMATCH , REGEXEXTRACT và REGEXREPLACE sử dụng các biểu thức chính quy để tìm, trích xuất hoặc thay thế văn bản trong một tập dữ liệu.
II. Về các hàm
REGEXMATCH
-
Chức năng: Kiểm tra xem văn bản có khớp với biểu thức chính quy hay không và trả về Boolean (TRUE hoặc FALSE).
-
Cú pháp: = REGEXMATCH (văn bản, biểu thức chính quy)
-
Lập luận:
-
Văn bản (bắt buộc): Văn bản được đánh giá
-
Biểu thức chính quy (bắt buộc): Văn bản được khớp
-
-
Ví dụ: = REGEXMATCH ("Sheets", "S.e") sẽ trả về TRUE
REGEXEXTRACT
-
Chức năng: Trích xuất văn bản phù hợp với biểu thức chính quy
-
Cú pháp: = REGEXEXTRACT (văn bản, biểu thức chính quy)
-
Lập luận:
-
Văn bản (bắt buộc): Văn bản được đánh giá
-
Biểu thức chính quy (bắt buộc): Văn bản được trích xuất
-
-
Ví dụ: = REGEXEXTRACT ("abcedfg", "c. * f") trích xuất tất cả văn bản từ c đến f (bao gồm c, f) trong chuỗi "abcedfg", sẽ trả về cedf .
REGEXREPLACE
-
Chức năng: Đối sánh một chuỗi văn bản và thay thế nó bằng một chuỗi văn bản khác
-
Cú pháp: = REGEXREPLACE (văn bản, biểu thức chính quy, văn bản thay thế)
-
Lập luận :
-
Văn bản (bắt buộc): Văn bản được đánh giá
-
Biểu thức chính quy (bắt buộc): Chuỗi văn bản được thay thế
-
Văn bản thay thế (bắt buộc): Văn bản sẽ thay thế chuỗi văn bản được chỉ định
-
-
Ví dụ: = REGEXREPLACE ("abcedfg", "a. * d", "xyz") sẽ trả về xyzfg
III. Cú pháp biểu thức chính quy
Vì các hàm này dựa vào biểu thức chính quy để thực hiện các hành động của chúng, điều quan trọng là phải hiểu cách viết biểu thức chính quy.
1. Ví dụ
Giả sử bạn cần trích xuất địa chỉ email từ một tập dữ liệu văn bản lớn. Mặc dù địa chỉ email tuân theo định dạng chuẩn, độ dài và kiểu ký tự được hỗ trợ trong các phần khác nhau khác nhau. Dưới đây là một cách biểu thức chính quy có thể được sử dụng để mô tả địa chỉ email:
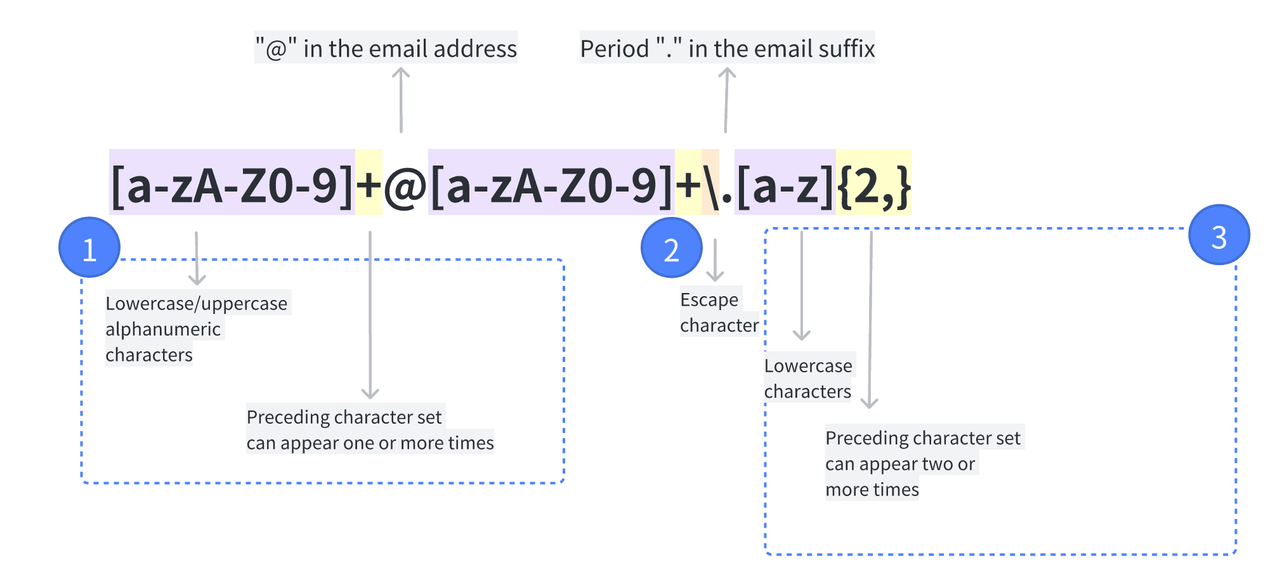
Nó có thể trông khó khăn lúc đầu, nhưng nó sẽ trở nên rõ ràng hơn nhiều sau khi bạn đã đi qua phần Metafigures phần dưới đây. Dưới đây là một sự cố cơ bản:
-
Phần 1: Mô tả tiền tố email: Một chuỗi chứa các chữ cái hoặc số. Dấu + ở đây chỉ ra rằng độ dài không cố định. Hậu tố email cũng tuân theo định dạng này, vì vậy biểu thức tương tự được sử dụng sau ký hiệu at (@).
-
Phần 2: Chỉ định rằng hàm sẽ tìm kiếm một khoảng thời gian (.) Trong hậu tố email ( xxx.com ). Vì một khoảng thời gian phục vụ một chức năng đặc biệt trong cú pháp, một ký tự thoát, dấu gạch chéo (\), phải được thêm vào phía trước. Lưu ý rằng biểu tượng at (@) trong ví dụ trước không phải là một ký tự đặc biệt, vì vậy không cần ký tự thoát.
-
Phần 3: Mô tả nửa sau của hậu tố email: Một chuỗi bao gồm hai hoặc nhiều chữ thường (chẳng hạn như tên miền email ".com").
Cũng giống như có nhiều cách khác nhau để giải các bài toán, có nhiều cách để viết một biểu thức chính quy để mô tả cùng một loại nội dung. Trên đây chỉ là một ví dụ. Để hiểu rõ hơn về cách viết các biểu thức chính quy, chúng ta sẽ đi sâu hơn vào cú pháp của nó:
2. Kết hợp chính xác
Hàm sẽ trả về một kết quả khớp chính xác nếu không có siêu ký tự nào được sử dụng. Ví dụ = REGEXMATCH ("Sheets", "se") có nghĩa là chúng ta đang tìm kiếm "se" trong "Sheets", sẽ trả về FALSE vì không tìm thấy kết quả khớp chính xác của "se".
3. Siêu ký tự
Siêu ký tự là các ký tự có ý nghĩa đặc biệt trong biểu thức chính quy. Trong ví dụ trên, nếu chúng ta thay đổi biểu thức chính quy thành "S.e" để công thức trở thành = REGEXMATCH ("Sheets", "S.e") , thì TRUE sẽ được trả về thay vì dấu chấm (.) Là một siêu ký tự đại diện cho bất kỳ ký tự nào không phải là dấu ngắt dòng. Và vì "Sheets" chứa "She", công thức với "S.e" sẽ trả về TRUE.
Matching rules : Từ trái sang phải theo mặc định. Nếu số lần lặp lại không được chỉ định, chỉ bộ giá trị đầu tiên khớp với biểu thức chính quy sẽ được trả về.
|
Thể loại
|
Ký tự
|
Mô tả
|
Ví dụ
|
|
Bộ ký tự
|
[]
|
Lớp nhân vật. Phù hợp với bất kỳ ký tự trong [] .
|
Công thức: = REGEXREPLACE (" Room231 ", " [0-9] ", "X")
Kết quả: RoomXXX
|
|
[^]
|
Lớp ký tự không được kiểm soát. Phù hợp với bất kỳ ký tự nào không có trong [^] .
|
Công thức: = REGEXREPLACE (" Room231 ", " [^ 0-9] ", "X")
Kết quả: XXXX231
|
|
|
Lặp lại
|
*
|
Đối sánh các ký tự hoặc biểu thức phụ trước "*" xảy ra 0 lần trở lên. Thường được sử dụng để thể hiện bất cứ điều gì.
|
Công thức: = REGEXMATCH (" Sheets ", " [0-9] * ")
Kết quả: TRUE
|
|
+
|
Đối sánh các ký tự hoặc biểu thức phụ trước "+" xảy ra 1 lần trở lên.
|
Công thức: = REGEXMATCH (" Sheets ", " [0-9] + ")
Kết quả: FALSE
|
|
|
?
|
Đối sánh các ký tự hoặc biểu thức phụ trước "?" xảy ra 0 hoặc 1 lần. Thường được sử dụng để thể hiện bất kỳ nội dung nào là tùy chọn.
|
Công thức: = REGEXMATCH (" Sheet ", " Sheets? ")
Kết quả: TRUE
|
|
|
{}
|
Được sử dụng để kiểm tra số ký tự hoặc biểu thức phụ trước "{}" được lặp lại. "{n}" có nghĩa là lặp lại n lần ("n" đại diện cho một số). "{n, m}" có nghĩa là lặp lại n đến m lần. "{n,}" có nghĩa là lặp lại n đến vô số lần. Lưu ý rằng "n" và "m" phải là số nguyên dương.
|
Công thức: = REGEXREPLACE (" Sheets ", " e {2} ", "X")
Kết quả: ShXts
|
|
|
Biểu thức phụ
|
()
|
Biểu thức bên trong "()" sẽ trở thành một biểu thức phụ và sẽ được khớp toàn bộ.
Hơn nữa, dấu ngoặc đơn cũng có thể được sử dụng để thu thập dữ liệu. Xem Phần 4 để biết thêm thông tin.
|
Công thức: = REGEXMATCH (" 12344@hotmail.com ", " @ (hotmail | gmail)\ .com ")
Kết quả: TRUE
|
|
Hoặc nhà điều hành
|
|
|
Đối sánh nội dung trước hoặc sau "|".
|
|
|
Nhân vật trốn thoát
|
\
|
Đối sánh các ký tự sau "\". Chủ yếu được sử dụng cho các ký tự cũng có ý nghĩa siêu ký tự . Ví dụ: nếu bạn muốn khớp dấu ngoặc đơn, bạn cần nhập " \ ( ". Nếu bạn muốn tìm dấu chấm, hãy nhập " \. ".
|
Công thức: = REGEXREPLACE (" Sheet.Best. Công cụ ", " \. ", "")
Kết quả: Sheet Best Tool
|
|
Mỏ neo
|
^
|
Khớp với phần đầu của một chuỗi.
|
Công thức: = REGEXREPLACE (" abc123abc ", " ^ abc ", "ABC")
Kết quả: ABC123abc
|
|
$
|
Khớp với phần cuối của một chuỗi.
|
Công thức: = REGEXREPLACE (" abc123abc ", " abc $ ", "ABC")
Kết quả: abc123ABC
|
|
|
Các ký tự và bộ ký tự chung
|
.
|
Khớp bất kỳ ký tự nào ngoại trừ ngắt dòng (\ n).
|
S.e phù hợp với She, S2e, S@e
|
|
[a-z]
|
Khớp bất kỳ chữ cái nào trong số 26 chữ cái thường.
|
Công thức: = REGEXEXTRACT (" Sheets ", " [a-z] + ")
Kết quả: heets
|
|
|
[^ a-z]
|
Khớp bất kỳ ký tự nào không phải là chữ thường.
|
Công thức: = REGEXMATCH (" tờ ", " [^ a-z] ")
Kết quả: FALSE
|
|
|
[A-Z]
|
Khớp bất kỳ chữ cái nào trong số 26 chữ cái viết hoa.
|
Công thức: = REGEXEXTRACT (" Sheets ", " [A-Z] ")
Kết quả: S
|
|
|
[0-9]
|
Ghép bất kỳ số nào từ 0 đến 9.
|
Công thức: = REGEXMATCH (" Sheets ", " [0-9] ")
Kết quả: FALSE
|
|
|
\ w
|
Phù hợp với bất kỳ ký tự chữ và số cũng như dấu gạch dưới. Tương đương với [A-Za-z0-9 _] .
|
Công thức: = REGEXEXTRACT (" email@mail ", " \ w @\ w ")
Kết quả: l@m
|
|
|
\ W
|
Phù hợp với bất kỳ ký tự không chữ và số. Tương đương với [^ A-Za-z0-9 _] .
|
Công thức: = REGEXEXTRACT (" email@mail ", "\ W ")
Kết quả: @
|
|
|
\ d
|
Đối sánh số đầu tiên, tương đương với [0-9] .
|
Công thức: = REGEXEXTRACT (" email123@mail ", " \ d ")
Kết quả: 1
|
|
|
\ D
|
Khớp với số không đầu tiên, tương đương với [^ 0-9] .
|
Công thức: = REGEXEXTRACT (" email123@mail ", " \ D ")
Kết quả: e
|
|
|
\ s
|
Khớp bất kỳ khoảng trống nào bao gồm khoảng trắng và nguồn cấp dữ liệu biểu mẫu. Tương đương với [\ f\ n\ r\ t\ v] .
|
Công thức: = REGEXREPLACE (" Sheet Best ", " \ s ", "")
Kết quả: SheetBest
|
|
|
\ S
|
Phù hợp với bất kỳ không gian trống. Tương đương với [^\ f\ n\ r\ t\ v] .
|
Công thức: = REGEXREPLACE (" Sheet Best ", " \ S ", "A")
Kết quả: AAAAA AAAA
|
|
|
\ b
|
Khớp với một ranh giới từ. Đây có thể là dấu cách trước hoặc sau một từ, hoặc bắt đầu hoặc kết thúc câu.
|
Công thức: = REGEXREPLACE (" rico và coco ", " \ bco ", "AA")
Kết quả: rico và AAco
|
|
|
\ B
|
Khớp một ranh giới không phải từ.
|
Ví dụ, er\ B khớp " er " trong động từ nhưng không khớp " er " ở cuối không bao giờ .
|
|
|
\ f
|
Phù hợp với một nguồn cấp dữ liệu biểu mẫu.
|
-
|
|
|
\ t
|
Phù hợp với một tab.
|
-
|
|
|
\ v
|
Phù hợp với một ký tự tab dọc.
|
-
|
4. Quan sát
Nhìn trước và nhìn sau, được gọi chung là nhìn xung quanh hoặc xác nhận, được sử dụng để kiểm tra xem bắt đầu và kết thúc của chuỗi có đáp ứng các điều kiện biểu thức chính quy hay không. Chúng không nắm bắt văn bản, mà trả về kết quả phù hợp. Điều kiện nhìn xung quanh cần được đặt trong dấu ngoặc đơn. Hai phương pháp sau được hỗ trợ:
|
Thể loại
|
Cú pháp
|
Mô tả
|
Ví dụ
|
|
Nhìn về phía trước tích cực
|
(? = điều kiện regex)
|
Cú pháp: Biểu thức chính quy 1 (? = biểu thức chính quy 2) khớp và trả về nội dung đáp ứng biểu thức chính quy 1 và được theo sau bởi nội dung đáp ứng biểu thức chính quy 2.
|
Công thức:
= REGEXREPLACE ("abc123abc456", " abc (? = 123) ", "ABC")
Kết quả: ABC 123abc456
|
|
Nhìn xa trông rộng tiêu cực
|
(?! biểu thức chính quy)
|
Cú pháp: Biểu thức chính quy 1 (?! Biểu thức chính quy 2) khớp và trả về nội dung đáp ứng biểu thức chính quy 1 và được theo sau bởi nội dung không đáp ứng biểu thức chính quy 2.
|
Công thức: = REGEXREPLACE ("abc123abc456", " abc (?! 123) ", "ABC")
Kết quả: abc123 ABC 456
|
5. Nhóm và chụp (sử dụng dấu ngoặc đơn)
Nội dung được đặt trong ngoặc đơn trở thành một nhóm. Nhóm bao gồm nhóm chụp và nhóm không chụp:
-
Các nhóm chụp được sử dụng để khớp và chụp kết quả trong ngoặc đơn.
-
Các nhóm không chụp được sử dụng để khớp các kết quả không được chụp, có nghĩa là chúng không thể được sử dụng cho các phép tính thứ cấp.
|
Thể loại
|
Cú pháp
|
Ví dụ về công thức
|
Kết quả
|
Ghi Chú
|
|
Không nhóm
|
-
|
= REGEXEXTRACT ("Sinh nhật20220104", " sinh nhật2022\ d + ")
|
sinh nhật20220104
|
Trả về kết quả hoàn chỉnh
|
|
Nhóm chụp
|
(Biểu thức chính quy)
|
= REGEXEXTRACT ("Mybirthday 20220104", " sinh nhật ( 2022\ d + ) ")
|
20220104
|
Chỉ trả về kết quả trong ngoặc đơn
|
|
Nhóm không chụp
|
(?: Biểu thức chính quy)
|
= REGEXEXTRACT ("Mybirthday 20220104", " sinh nhật (?: 2022 ) ( \ d + ) ")
|
0104
|
Sử dụng (?:) sẽ dẫn đến một trận đấu nhưng sẽ chỉ trả về kết quả trong dấu ngoặc đơn.
Hơn nữa, khi chỉ có các nhóm không chụp trong biểu thức chính quy, kết quả hoàn chỉnh sẽ được trả về.
|
Dưới đây là một số mẹo nhóm thực tế:
-
Nhiều nhóm:
Khi sử dụng REGEXEXTRACT để trích xuất nội dung, nhiều cột có thể được trích xuất thông qua nhiều nhóm cùng một lúc. Như hình dưới đây, nội dung được nhóm thành ba cột thông qua ba bộ dấu ngoặc đơn.
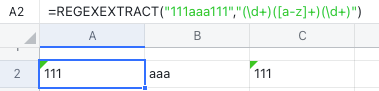
Hơn nữa, các nhóm có thể được lồng vào nhau (như trong ví dụ bên dưới). Các nhóm lồng nhau có thể được chia thành 4 cột.
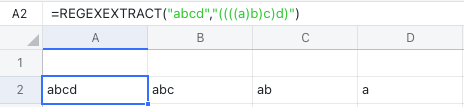
-
Phản hồi:
Nhập \ n sau một nhóm (n phải là số dương) để hoạt động như một tham chiếu giá trị cho nhóm này, vì vậy bạn có thể sử dụng (.)\ 1 để khớp hai số lặp lại liên tiếp.

